May 1, 2026
OCR System for Automated Check Deposit
A production OCR system for extracting printed and handwritten cheque data in low-resource language environments using a hybrid edge-cloud architecture.
Overview
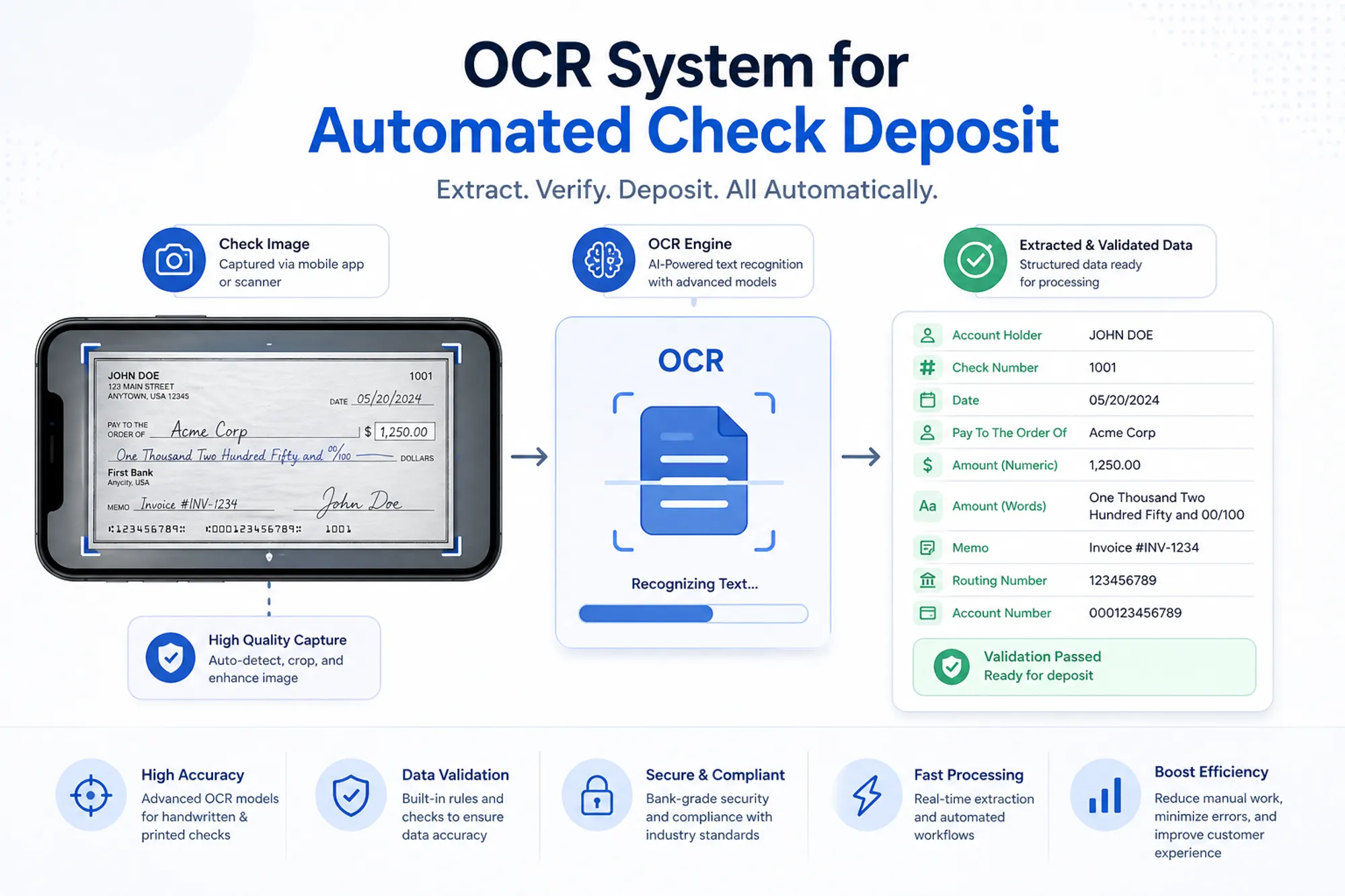
Developed a production-ready OCR system to automate cheque processing for a mobile banking application. The system extracts both printed (MICR) and handwritten fields from cheque images captured in uncontrolled environments.
The solution was designed for low-resource language support (Sinhala, Tamil) and built using a hybrid edge + cloud architecture, balancing latency, accuracy, and infrastructure constraints typical of emerging markets.
Problem
- Manual cheque verification required ~10 minutes per transaction, limiting throughput.
- Mobile capture introduced high variability (lighting, blur, perspective distortion).
- Handwritten fields (amount, payee) were inconsistent and error-prone to extract.
- Existing OCR solutions had poor support for Sinhala and Tamil scripts, especially handwritten forms.
Constraints
- High input variability from mobile devices in real-world conditions.
- Limited availability of labeled datasets for Sinhala and Tamil handwriting.
- Strict accuracy requirements for financial transactions (field-level correctness critical).
- Latency requirements for near real-time user feedback.
- Infrastructure constraints requiring efficient use of compute and bandwidth.
Approach
Designed a two-stage OCR pipeline separating concerns between input quality and text extraction:
On-device preprocessing (edge):
- Image validation and quality gating
- Perspective correction and normalization
- Early rejection of low-quality captures
Cloud-based OCR pipeline:
- Printed text extraction using deterministic + classical CV methods
- Handwritten text recognition using deep learning models (CRNN-style sequence models)
- Field-level structuring and confidence scoring
A human-in-the-loop validation layer was introduced to ensure correctness for financial operations.
System Design
The system follows a hybrid processing architecture:
Edge (Mobile Device):
- Cheque boundary detection using contour-based methods
- Perspective correction to canonical top-down view
- Image normalization (contrast adjustment, denoising)
- Quality scoring to prevent invalid uploads
Cloud Pipeline:
- Preprocessing: binarization and noise reduction
- Printed field extraction:
- MICR line parsing using rule-based + CV techniques
- Handwritten field extraction:
- Sequence-based OCR model (CNN + RNN encoder-decoder)
- Trained on augmented datasets with synthetic variations for Sinhala/Tamil scripts
- Post-processing:
- Field validation (amount consistency, format checks)
- Confidence scoring per field
Output Layer:
- Structured fields presented to user/operator
- Human validation required for low-confidence predictions
Key Decisions
Hybrid Edge + Cloud Architecture
Pushing preprocessing to the device improved OCR accuracy by standardizing inputs and reduced unnecessary cloud processing by filtering invalid captures early. This was critical given bandwidth and latency constraints.
Separate Printed and Handwritten Pipelines
Printed MICR extraction is deterministic and highly reliable, while handwritten recognition requires probabilistic models. Decoupling these paths improved accuracy and allowed independent iteration.
Optimize for Data Quality over Model Complexity
Given limited labeled data for Sinhala and Tamil handwriting, improvements in preprocessing and data augmentation had a larger impact than increasing model complexity.
Human-in-the-Loop as a First-Class Component
Full automation was not viable given financial risk. Instead, the system was designed to maximize automation up to a confidence threshold, with human verification handling edge cases.
Results & Impact
- Processing Time: Reduced from ~10 minutes → ~30 seconds per cheque
- Field-Level Accuracy:
- Printed fields: >98%
- Handwritten fields: ~85-90% (varied by script and quality)
- Operational Efficiency: Significant reduction in manual verification workload
- Product Impact: Enabled scalable mobile cheque deposit capability in a previously manual workflow
This system transformed cheque processing into a semi-automated, high-throughput pipeline, while maintaining the reliability required for financial transactions.
Tradeoffs
- Handwritten OCR accuracy remained the primary bottleneck, especially for Tamil compound characters.
- Cloud dependency introduced latency and required stable connectivity.
- Human validation added slight overhead but was necessary for correctness.
- Limited training data constrained model generalization for edge cases.
Learnings
- In OCR systems, input normalization and data quality often outperform model improvements.
- Supporting low-resource languages requires investment in data generation and augmentation, not just model architecture.
- Hybrid edge-cloud systems are effective when balancing latency, cost, and accuracy in mobile-first environments.
- Designing for confidence-based automation is more practical than aiming for full automation in high-risk domains.
Future Work
- Improve handwritten OCR using larger labeled datasets and transformer-based architectures
- Expand support for complex script variations in Tamil and Sinhala
- Explore partial on-device inference to reduce latency
- Introduce adaptive confidence thresholds to further reduce manual verification