May 1, 2026
Research Paper Summarization and QA System using BERT
An end-to-end NLP system combining extractive summarization and question-answering to help users quickly navigate and understand research papers.
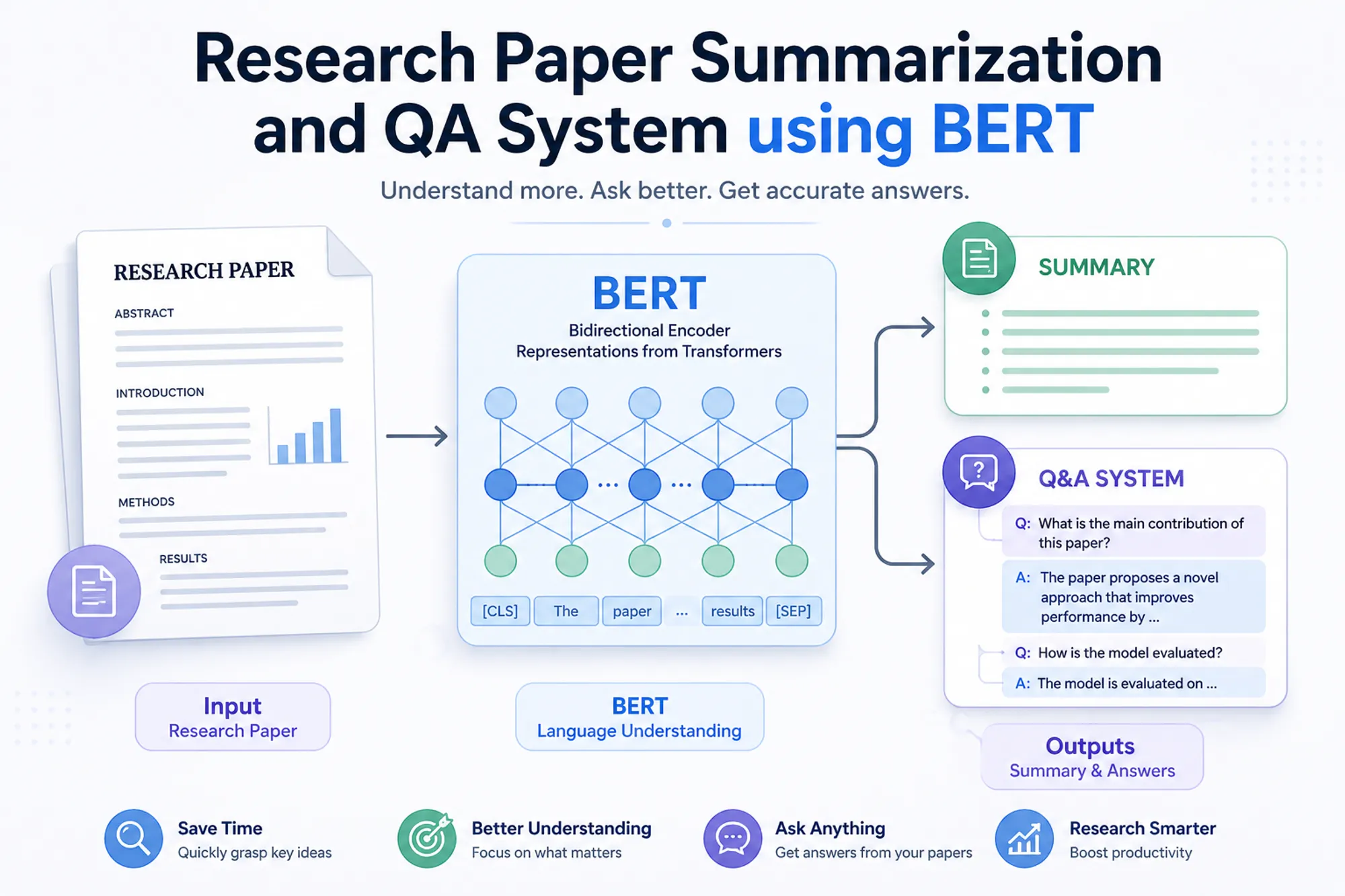
Overview
Designed and built an end-to-end research paper understanding system that combined extractive summarization and question-answering capabilities to help users quickly navigate long-form technical documents.
The system allowed users to:
- Generate concise summaries of research papers
- Ask targeted questions and retrieve contextually relevant answers
- Interact with complex documents through a simple web interface
This was developed as a prototype system (pre-LLM era) using BERT-based architectures and deployed fully on AWS.
Problem
- Research papers are long, dense, and time-consuming to navigate
- Users needed both high-level summaries and precise answers to specific questions
- Traditional keyword search failed to capture semantic meaning
- No unified system existed to both summarize and interact with documents
Constraints
- Documents often exceeded transformer token limits
- Required high factual accuracy (no generative hallucination)
- Limited labeled data for supervised summarization and QA
- Latency constraints for interactive usage in a web application
- Built prior to widespread availability of large generative models
Approach
Framed the system as a combination of:
- Extractive summarization for generating high-level document overviews
- BERT-based question answering for retrieving precise answers from text
Key components:
- Fine-tuned BERT-base for sentence ranking (summarization)
- Fine-tuned BERT QA model (SQuAD-style) for span-based question answering
- Document chunking strategy to handle long inputs beyond token limits
Rather than generating new text, the system focused on selecting and retrieving relevant information, ensuring factual consistency and reliability.
System Design
The system was designed as a lightweight, modular pipeline deployed on AWS:
- Documents are ingested and segmented into overlapping text chunks
- Sentence-level embeddings are generated using a BERT encoder
- A ranking layer selects top sentences to form summaries
- For QA:
- User queries are matched against document chunks
- A BERT QA model extracts answer spans from the most relevant sections
Deployment architecture:
- Frontend: Lightweight web application for document upload and interaction
- API Layer (AWS Lambda): Handles request orchestration and preprocessing
- Model Service: Hosts BERT models for summarization and QA inference
- Compute: GPU-backed instances for model inference (Elastic Beanstalk)
To handle long documents, chunk-level processing with aggregation was used to maintain both performance and coverage.
Key Decisions
Use extractive + retrieval-based QA instead of generative models
At the time, generative models were not reliable for factual domains.
An extractive + span-based QA approach ensured high precision and zero hallucination risk, which was critical for research content.
Build on BERT rather than lighter NLP methods
While classical methods (e.g., TextRank) were considered, BERT provided significantly better contextual understanding, especially for technical language.
Design for long-document handling early
Transformer token limits required explicit chunking and aggregation strategies.
This became a core part of the system design rather than an afterthought.
End-to-end ownership including web application
The system was built as a complete user-facing product, not just a model, ensuring usability and adoption.
Results & Impact
- Latency: ~1-3 seconds for summary generation; sub-second response for QA on indexed documents
- Efficiency: Reduced time to extract insights from research papers from ~30-60 minutes to under a minute
- Adoption: Enabled non-expert users to navigate technical content more effectively
- Consistency: Provided standardized summaries across documents without manual effort
This system demonstrated the viability of interactive document understanding systems prior to modern LLM-based approaches.
Tradeoffs
- Extractive summaries lacked fluency compared to generative methods
- QA was limited to retrieving spans rather than synthesizing answers
- Chunking introduced boundary limitations for cross-section reasoning
- BERT-based inference required careful optimization to meet latency targets
Learnings
- Combining multiple NLP capabilities (summarization + QA) significantly improves usability over standalone models
- Pre-trained transformer models can be effectively adapted for production use with limited data
- Handling long documents is a primary system design concern, not just a modeling issue
- End-to-end system design (UX + API + model) is critical for real-world impact
Future Work
- Introduce hybrid extractive + abstractive summarization pipelines
- Add semantic search / retrieval layers for better document navigation
- Incorporate user feedback loops to improve ranking and relevance
- Migrate to generative LLM-based approaches with guardrails for factual accuracy
Dive deeper
Technical deep dives
Posts that expand on techniques, systems, or modeling ideas used in this project.
Jul 28, 2019
Enjoyed this project?
Leave a quick reaction or share this project with someone who might find the work useful.